采用的策略是微软云服务的Python SDK + SSML
Azure上,语音部分的文档写的较为详细,包含各种功能,如文本转语音 REST API,TTS SDK,自定义语音模型进行文本转语音等。但是没有整体的、提纲般的介绍,看完文档极有不知如何下手。本文将一步步地介绍,如何从0开始使用Azure SDK的使用方法。我们希望实现的效果是,输入一段文本,调用SDK后,返回给我们一段wav格式的音频,播放后,即为之前输入的文本。
1、注册账号
注册微软Azure账号看这里:https://zhuanlan.zhihu.com/p/49711377
需要一张vasa信用卡,也可以是虚拟卡。对于国内用户,这是极不友好的。不过也有一些其他优惠,比如学生的,自行获取国外edu教育有效了,据说GitHub学生认证也可以,不过都比较麻烦。注册的时候最好使用非大陆的IP,比如香港的IP+香港的地址
2、创建资源

都选择白嫖免费使用的就完事,注意要选择美国东部的服务,eastus
其他的名称只要是不重复就可以随便填,填写好就可以看到自己的key了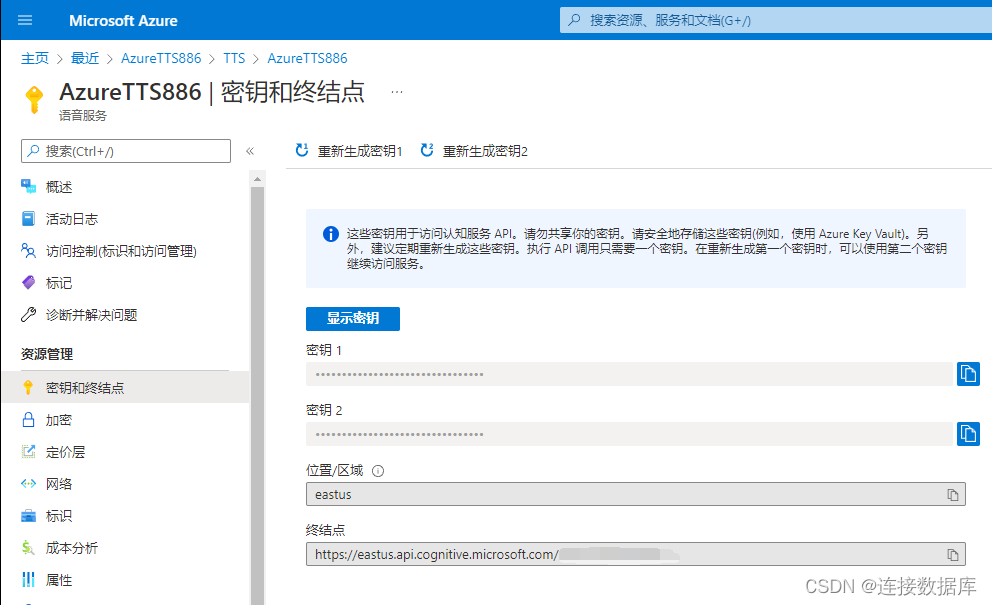
3、使用SDK
使用之前先安装SDK,Python就一条命令,很简单
1 | pip install azure-cognitiveservices-speech |

安装好就可以上代码了,有注释
1 | # Copyright (c) Microsoft. All rights reserved. |
参考
https://github.com/Azure-Samples/cognitive-services-speech-sdk/blob/master/samples/python/console/speech_synthesis_sample.py
https://zhuanlan.zhihu.com/p/437580699
https://www.bilibili.com/video/BV15a4y1W7re

